电商数仓 V2.0 (01 用户行为采集平台)
一、数据仓库概念
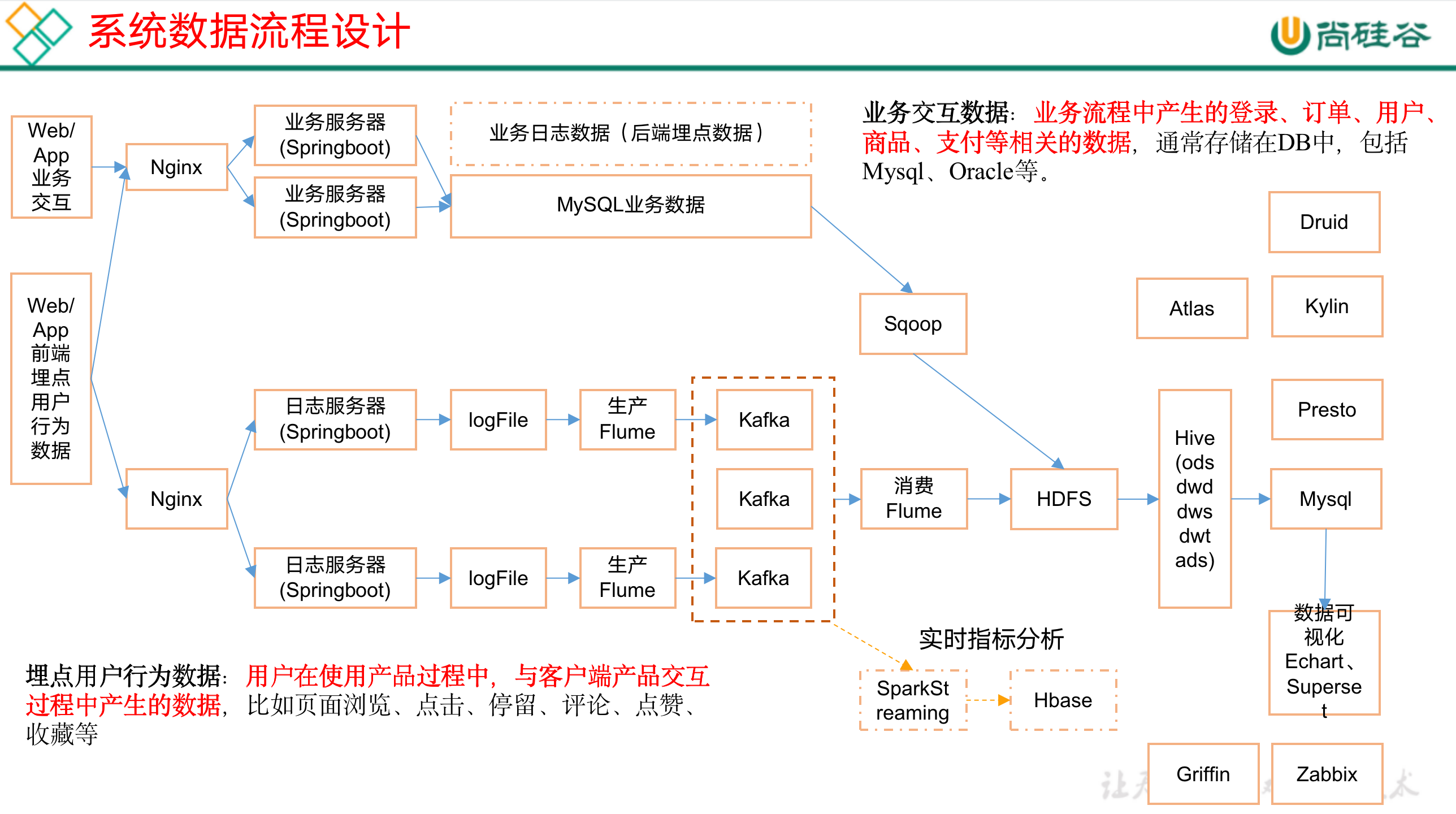
二、项目需求及架构设计
三、数据生成模块
执行
1
2
3
| java -classpath logcollecter-1.0-SNAPSHOT-jar-with-dependencies.jar com.shuofxz.appclient.AppMain > /dev/null 2>&1
java -jar logcollecter-1.0-SNAPSHOT-jar-with-dependencies.jar > /dev/null 2>&1
|
更改系统时间,用于生成不同日期的日志
(这个应该放到 java 代码中改吧)
1
2
|
sudo date -s 2021-01-11
|
四、数据采集模块
Hadoop
- 配置支持 lzo 压缩(先别搞,需要 lzo 编译的 hadoop 才能用)
需要先安装 lzo 库
1
| yum install lzo-devel lzop
|
将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
修改 etc/hadaoop/core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
|
将 jar 包 和 core-site.xml 同步到其他机器上
Zookeeper
flume 采集模块
1
2
3
4
|
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HADOOP_HOME=/opt/module/hadoop-2.7.2
|
- flume 中添加一个配置文件,用于指定 interceptor, channel 等
conf/file-flume-kafka.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| a1.sources=r1
a1.channels=c1 c2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume-1.7.0-bin/test/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.shuofxz.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.shuofxz.flume.interceptor.LogTypeInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
|
- 写一个 java,编写 ETL 和 类型拦截器
- 修改
conf/log4j.properties
1
2
3
|
flume.log.dir=/opt/module/flume-1.7.0-bin/logs
|
flume-f1.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume-1.7.0-bin/bin/flume-ng agent --conf /opt/module/flume-1.7.0-bin/conf --conf-file /opt/module/flume-1.7.0-bin/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.7.0-bin/flume.log 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
|
注意:
1
2
|
-Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.7.0-bin/flume.log 2>&1
|
注意:
flume-env.sh 中需要配置 flume_opts 到 hadoop common 目录,否则启动时报错
Kafka 日志收集
- flume 启动后就会往 kafka 里写数据,topic 也会自己创建
- 测试:执行之前创建的生成日志脚本
gen_logs.sh,如果可以在kafka中接收到新的数据,证明从日志生成 -> flume -> kafka 链路打通了
- 压力测试
1
2
3
4
5
|
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
|
1
| bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
|
1
2
3
4
5
| bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_start
bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --topic topic_start
|
Kafka 数据存储到 HDFS
conf/kafka-flume-hdfs.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_start
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r2.kafka.topics=topic_event
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume-1.7.0-bin/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume-1.7.0-bin/data/behavior1/
a1.channels.c1.keep-alive = 6
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/module/flume-1.7.0-bin/checkpoint/behavior2
a1.channels.c2.dataDirs = /opt/module/flume-1.7.0-bin/data/behavior2/
a1.channels.c2.keep-alive = 6
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| #!/bin/bash
case $1 in
"start"){
for i in hadoop104
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /opt/module/flume-1.7.0-bin/bin/flume-ng agent --conf-file /opt/module/flume-1.7.0-bin/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.7.0-bin/logs/f2_log.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop104
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| #! /bin/bash
case $1 in
"start"){
echo " -------- 启动 集群 -------"
echo " -------- 启动 hadoop集群 -------"
/opt/module/hadoop-2.7.2/sbin/start-dfs.sh
ssh hadoop103 "/opt/module/hadoop-2.7.2/sbin/start-yarn.sh"
/opt/module/zookeeper-3.4.10/bin/zk-all.sh start
for (( i=0; i<6; i++ ));do
echo "wait... $i"
sleep 1s;
done
/opt/module/flume-1.7.0-bin/bin/flume-f1.sh start
/opt/module/kafka_2.12-2.3.1/bin/kafka-all.sh start
sleep 6s;
/opt/module/flume-1.7.0-bin/bin/flume-f2.sh start
};;
"stop"){
echo " -------- 停止 集群 -------"
/opt/module/flume-1.7.0-bin/bin/flume-f2.sh stop
/opt/module/kafka_2.12-2.3.1/bin/kafka-all.sh stop
sleep 10s;
/opt/module/flume-1.7.0-bin/bin/flume-f1.sh stop
/opt/module/zookeeper-3.4.10/bin/zk-all.sh stop
echo " -------- 停止 hadoop集群 -------"
ssh hadoop103 "/opt/module/hadoop-2.7.2/sbin/stop-yarn.sh"
/opt/module/hadoop-2.7.2/sbin/stop-dfs.sh
};;
esac
|
1
| change_date.sh 2020-03-10
|
1
2
3
4
5
6
7
| #!/bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo "========== Change Date $i =========="
ssh -t $i "sudo date -s $1"
done
|
1
2
3
4
5
6
| #!/bin/bash
for i in hadoop102 hadoop103;do
echo "====== generte $i log ======="
ssh $i "java -jar /opt/project/data_warehouse_v2/logcollecter-1.0-SNAPSHOT-jar-with-dependencies.jar $1 $2 > /dev/null 2>&1 &"
done
|
启动后,日志经历 file -> flume -> kafka -> flume -> hdfs,最终会输出到配置的hdfs://origin_data/gmall/log/topic_event/%Y-%m-%d中
如果要删掉原来的重新采集的话,1)kafka 注意删除的时候把 topic 删除完全,去 Zookeeper 中看是否还有该 topic 记录;2)flume 要重新消费